

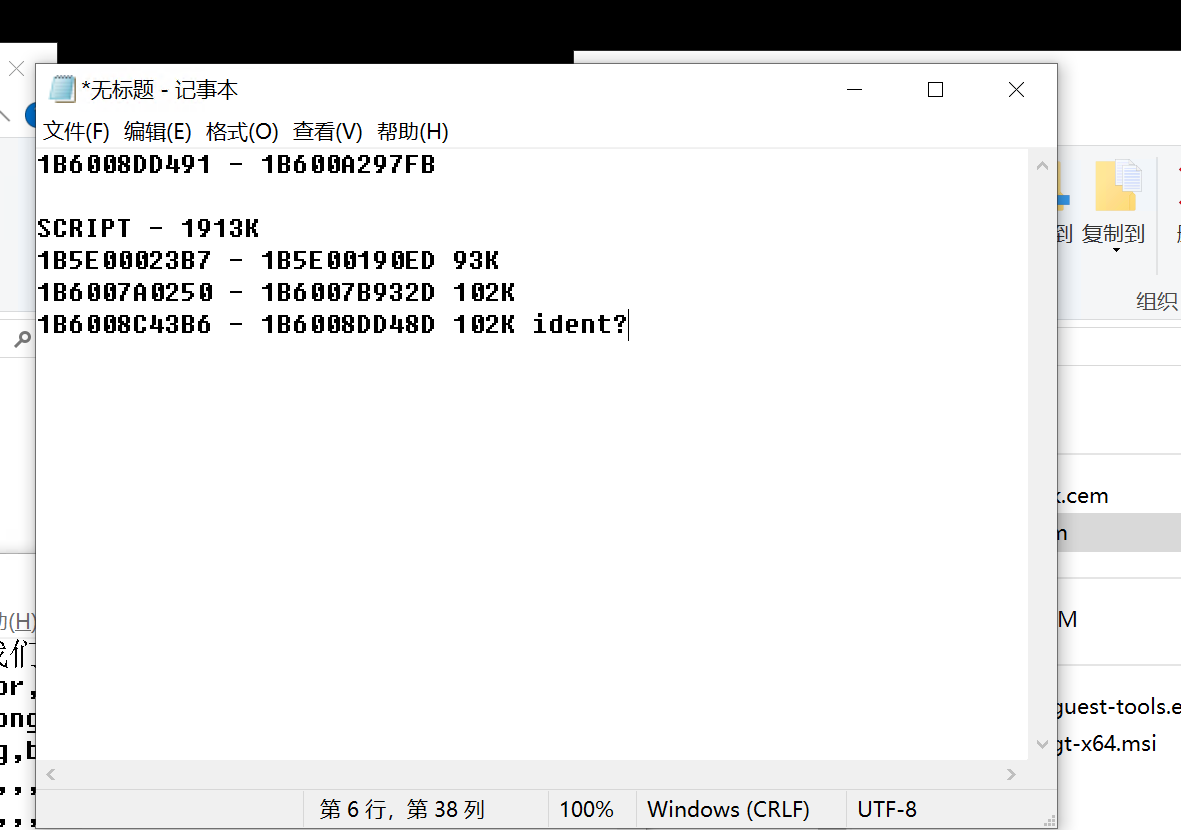
又让我研究了一个晚上终于研究出点儿名堂来了,我日了,把我当猴耍啊,图一是通过内存读取器大致判断出的明文对话的内存地址,这个游戏的加载逻辑大概是这样的:
1. 首先是把整个的密文(script.txt)加载在内存中(图一的第一行基本是密文被加载的地址区间),通过 assetstudio dump 出来的密文 script 大致是 1913K。
2. 其次,它会按章节把这个密文从全部密文中读取出来以后,按章节加载对应章节的部分,解密成明文放在内存中(102K 的那两个地址区间就是第一章的明文,只是不知道什么原因被加载了2次)。
3. 每次切换章节的时候,都会从密文中把对应章节的段落取出来以后解谜成明文,放在内存当中。
所以一开始,说的不知道去哪儿找,不知道加载完了没有的问题就得到了解决。
至于唐语歌给爷推荐的书目,大概不需要重新打一遍二周目才能知道了,思路大致如下:
1. 先要到一个完美存档,导入目录中,然后对照着网上的全流程视频和你 assetstudio 解包出来的章节对应表,使用游戏自带的读档系统加载和唐语歌有关系的章节
2. 把章节打开让对话显示起来,这个时候根据网上的实况视频中的字符串,搜索游戏里面的字串,找出对应的内存地址区间
3. 用 cheatengine 取出对应的地址区间,保存下来以后稍加修饰就得到了未经加密的 csv。
4. 写一个简单的小脚本:
- 匹配 csv 中说话人是唐语歌的行
- 从说话内容中匹配书名号
- 打印。
这样下来应该不用打二周目了,虽然还是有点复杂,但起码不用弄三四天了。
{kind=link}
然后想了想 这可能就是是否能够接受的问题。
学习也是一样,大家都使用的同一个教材(比如这个视频)做同一件事情(比如学打这个游戏),有些人打得六,有些人打得很痛苦,原因大抵如此。
要接触文化作品思路和心情就不可避免地会受影响,玩完或者看完感觉怅然若失或者莫名冲动是正常现象,正确对待就好
Spotify Shadowrocket 规则坏掉了。
买电视可以去看一下康佳家的。这个牌子专门有没广告的电视版本可以选,以 50 寸的电视为例,没广告的 1600 块钱,有广告的 1300 块钱。之前不知道哪儿看的,说现在要支持高清 4k 分辨率就必须要装智能系统,现在看来这就是鬼扯。虽然这牌子没广告的加价非常恶心,但好歹还有的选。他家没广告的是一个叫 D&Q 的子品牌,Konka 的看起来全是那种花里胡哨的智能电视。官方旗舰店上可能找不到,没上架藏得比较深,你得要问一下客服,让他给你一个这个玩意儿的链接才行。
我发现阿里真是吊啊!!!!我现在能用浏览器在咸鱼上买东西了!!!!!这简直就是外星科技呀!!!
我看他们米游前瞻视频里面大伟哥穿的那件衣服很不错,something new, something exciting, something out of imagination
想买
想买
想买
爷tm好尼玛想玩这个七圣召唤呀!
我找了一下中国国产处理器的有关情况
https://zh.wikipedia.org/zh-cn/%E4%B8%AD%E8%8A%AF%E5%9B%BD%E9%99%85
看了一下,之前说的似乎不对,网站上写的 200 mm 应该不是制程,而是每个晶圆尺寸的大小,而制程是达到了 7nm,只不过秘而不宣。
之所以能够取得这种高级制程,乃是因为中芯从台积电挖了一个叫梁孟松的,他和他的团队使得中芯国际成为继英特尔、台积电和三星之后,第四个能够量产 7nm 制程工艺的芯片制造厂商
所以在国内,在取得 arm64 IP 授权的前提下,先进制程的芯片是可以做出来的,而且技术相当先进,这个已经相当于英特尔 2023 年的水平
等爷有钱了爷要天天去各种小城市,地图上找不到的那种旅游。
“快看,文化输出
“快看,狮子
“快看,京剧
“耶~耶~耶~~~”
这个东西写得好的话就是《日月前事》级别的大作了,考虑到实际的驾驭能力,可以写成单元剧或者短篇集合,不一定一上来就长篇大论的。日月前事总共才多长么,没有多长
等此间事了,爷要去试着写同人小说。爷要把爷这十几年的经历全部安插在一个神奇的世界观里,分散安排给爷喜欢的角色,就像写童话故事一样,用这种神奇隐写术告诉地球人 这十多年来爷都经历了什么
估计会很有意思
四迹 在 b 站的个人签名如下
“平时不怎么看二次元,二次元浓度不高 ,平时喜欢 旅游、时尚、品牌、美食、消费、明星娱乐、理财、体育、精致生活、政治经济哲学等”
不能再买了……
今天为啥跌这么多呢
{kind=link}
something new, something exciting, something out of imagination
- 玩
- Noteshelf 3
- 喜欢
- 昔涟/唐语歌/三月七
- 输入法
- 小鹤双拼
- 当前版本
- 0.1.0
春来遍是桃花水,不辨仙源何处寻
加入于 2024年03月
