

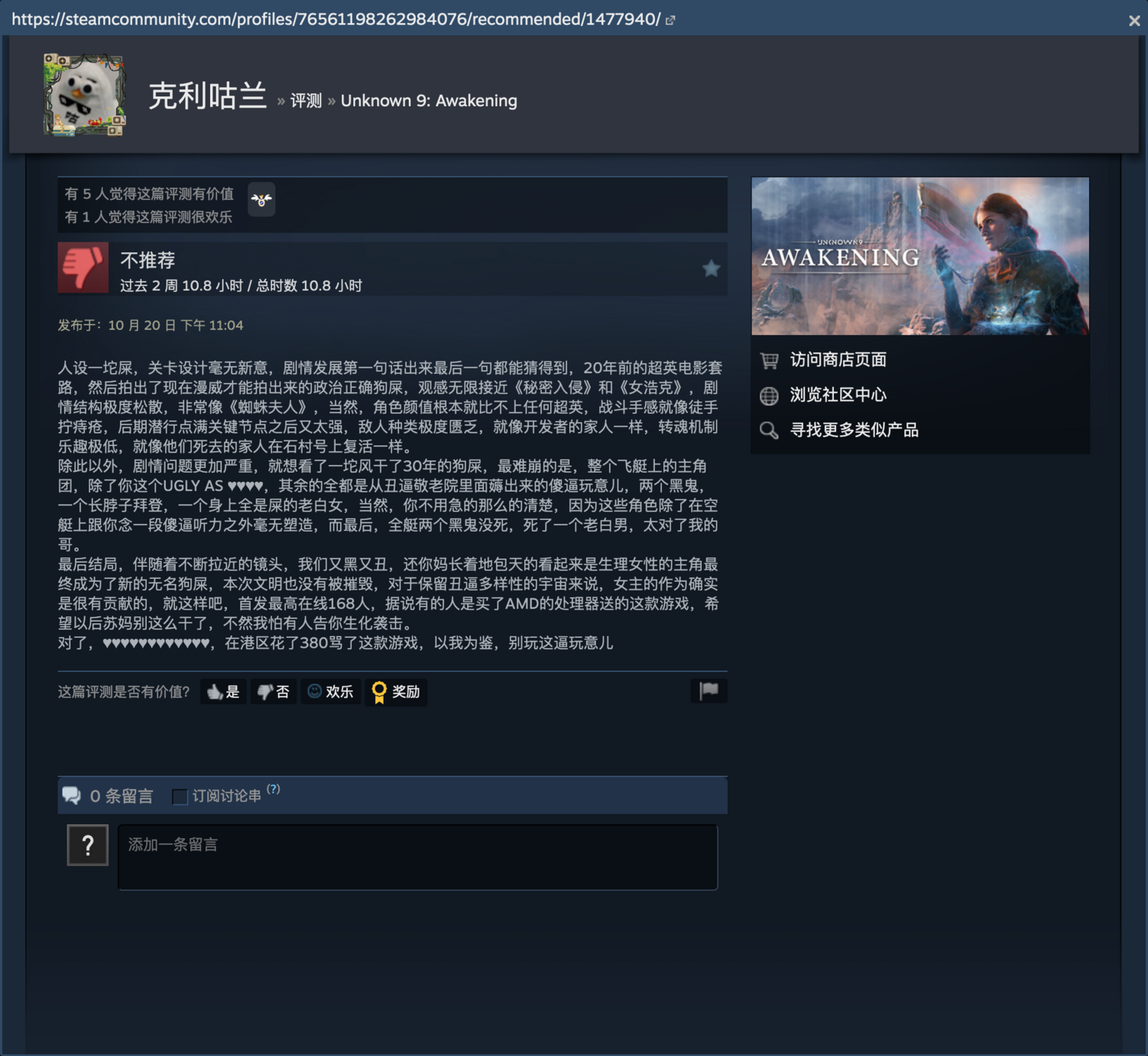
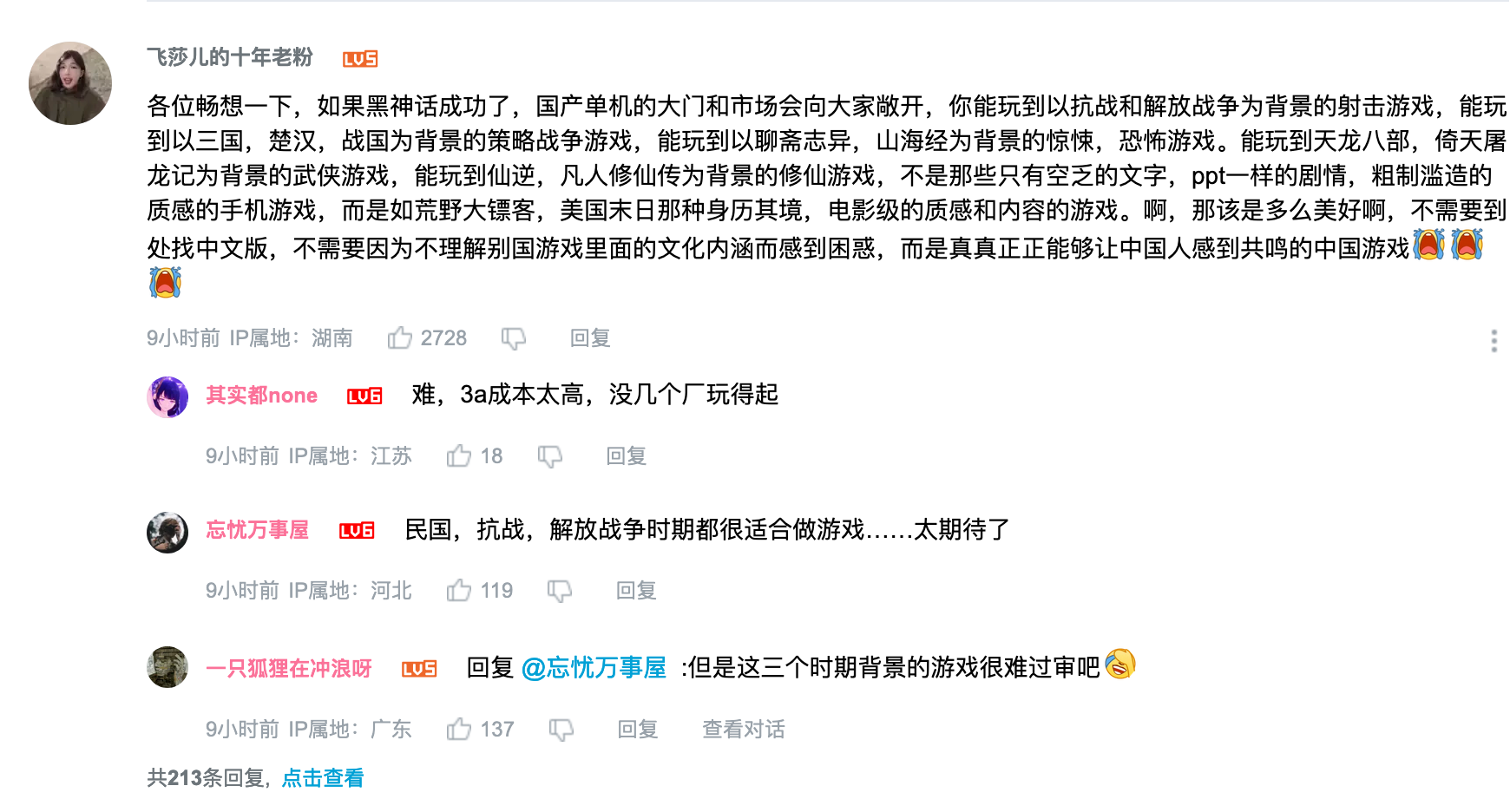
草台班子
又 tm 惊讶了,美国政府网站上同一篇文件发了两遍,一模一样的,我拿 diff 工具 检查了,就是一样一样的东西发了两遍。
卧槽,你敢想象中国的政府网站草台到把习哥的一篇文件发两遍,两遍的 URL 还不一样的么
真的神奇 太草台了
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Deepseek 为何敢“开源”而仍能获得商业成功
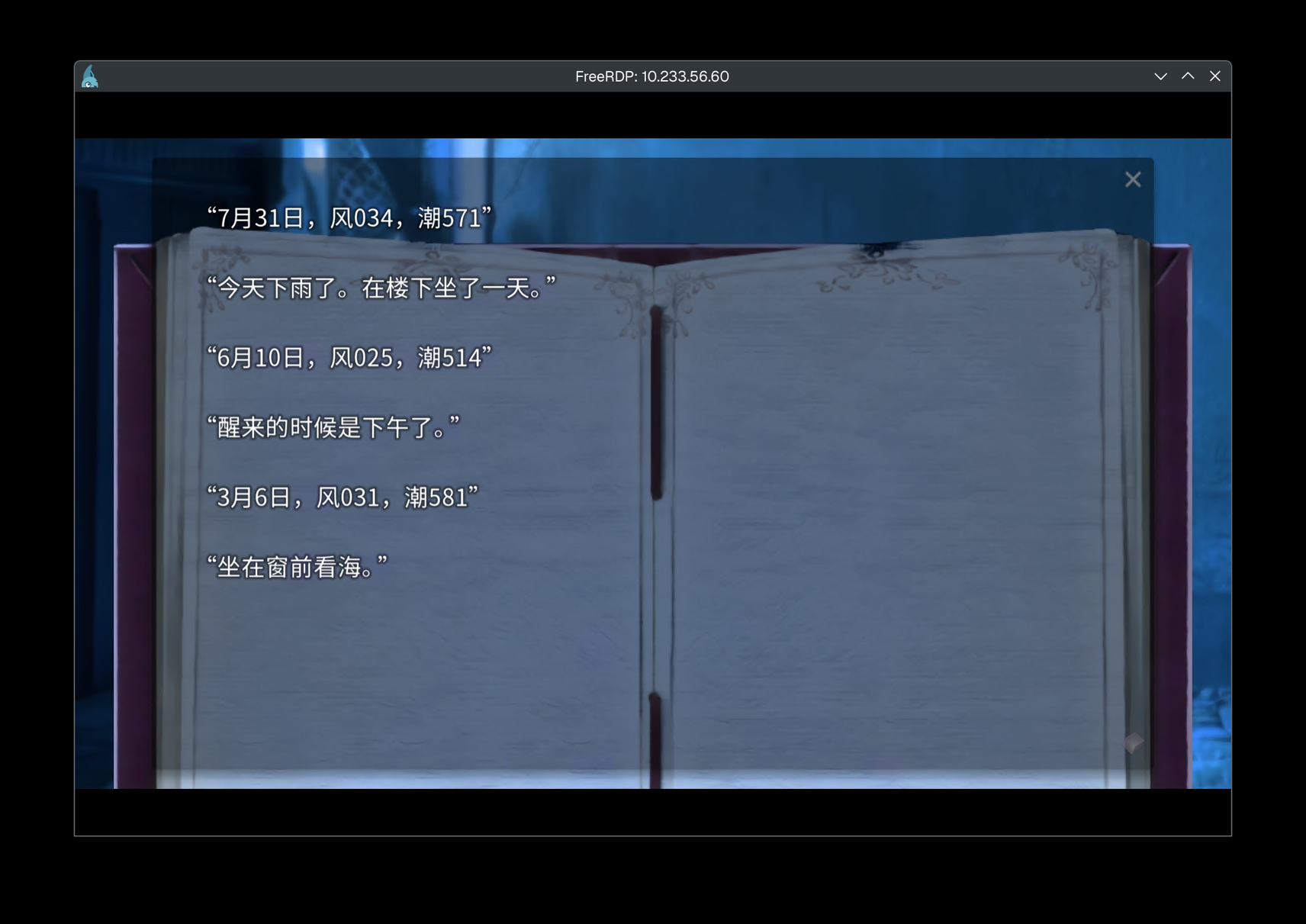
不必看到 deepseek 本身的模型,只需要请大家看一下这张自训练的规模不那么大的模型图,它的基座(我理解是相当于人类的常识)是来自于一个叫 Yi 的东西,而数据集据这个模型的作者所说,只来自于夜羊社的一部视觉小说中的文本,并且放出了训练用的脚本,在这里: https://huggingface.co/datasets/nenekochan/yoruno-vn
哪怕只有这么一个小模型,如图所示你自己加一下预训练的数据都有 12 GiB,这么大的文件实则不是驱动 AI 运行的真实的代码,而是所谓的“训练检查点”,顾名思义,就是我用专门的算力帮你:
1. 从原始数据当中取出能被训练的部分
2. 调用神经网络框架(Tensorflow 之类的)和一个训练工具代码(这个代码应该是开源的),帮你把数据从原始的你能看懂的,“训练”成一个机器才看得懂的二进制的鬼东西(向量的集合),达到一个可供使用的状态。
然后呢?你可以接着我训练的东西拿你的算力继续训练,也可以拿来直接用。
注意!这个过程步骤 2,更加类似于我们传统软件当中的“编译”步骤,而人是不可能看得懂这种“编译”产物的,在常规软件中,人用二进制编辑器从二进制开始逆向,尚且有可能看得懂一个规模有限的可执行文件,但这个检查点的大小是 12 GiB!!!
这就像什么呢,你从 Steam 上下下来一个黑神话悟空,然后把它的打包文件二进制拿出来,用 IDA Pro 打开,试图发现里面有什么。
比这个还难玩儿!!!
这种情况下,人有没有这种能力按照 MIT 协议给他的权利审阅代码,审阅检查点里面有什么?没有。如果你想要直接打开这个文件,就像图二一样你就会得到一个打不开的东西。
是故,这条道路是走不通的
而更要命的是什么?是计算机在传统的软件开发中作为一个得到输入就能预测输出的系统,甚至在给定条件的情况下,你可以产出完全“可复现”的构建——在给定的条件下使用给定的代码和编译器编译,生成的产物,sha256 校验值是完全一样的,有兴趣的可以去找一下 reproducible build——在 AI 大模型的情况下,不适用了:
1. 人没法通过上述“编译产物”了解 AI 是如何从输入导致输出的;
2. 分析源码,完全不懂的用户还起码能把它当个英语阅读题做做;但是要分析“编译产物”,工作量之庞大,运作机制之不明确,使得完全没有可操作性。
就举个例子,假如你看完了 MySQL 服务器的代码,你就可以自信地在简历里写“精通 MySQL”。但对 AI 模型,做得到吗?不行,没有这个能力知道吧。
3. 甚至将同样的输入上送给在同样的机器上跑着的同样 AI,得到的结果甚至都有可能不一样,你随便试试就知道了,也就是说,从“输入”变成“输出”,也是一个玄学的“编译”过程,具有很强的不确定性。
因而,深度求索公司会怎么样?
把编译过的二进制放出来,假模假式地允许你去看。
但你看到的是乱码,是英语阅读,还是二进制的天书,还是别的什么,它又不用管——即便是传统软件的源代码,要是它居然也是好审核的,就不会出 xz-utils 供应链投毒这种安全事件了。
所以!哪怕深度求索有一万个愿意希望你能够理解 AI 的实现原理,你也获取不到。
因而一般用户获得的是什么呢,只有它模型在理论上的私有化部署能力。
而当他们面临实际部署问题的时候马上就要面对一个更要命的问题:
算力不够。。。。
Deepseek 确实把 AI 所需要的算力打下来了,但那是针对厂商而言。。。。。。。。。
就,比如说之前需要 10000 个显卡算力才够对外提供 API 服务,现在给你减缩到 5000 个卡。
好嘛,你让一个在家里部署 Deepseek 的用户自己找 5000 个卡去?
当然,有人是把模型确实下下来跑了的,他用的是什么呢:2 个 Mac Studio 组成分布式的算力去跑,然后,并没有跑起来
https://www.youtube.com/watch?v=ILCWYy2_wFQ
怎么办 只好用他家给的官方 API 接口了
反正证明也证毕了,我深度求索就是很牛皮,你看不懂那又不是我的问题,你看不看得到英语阅读和我又什么关系,反正证毕了,QED 了,买我的服务,搞快搞快。
注意,不只是深度求索,由于大模型这种东西本身的特性,一切声称的所谓开源都是假开源的,因为用户无法按照现行开源协议看到大模型里面都有什么,更遑论理解,遑论造个新的,甚至遑论本地部署,那不是一个废的东西吗。就是这样,懂了吧?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
在玩儿《大鹏》
这个老师。配音配得挺一言难尽的。一点儿没有我记忆当中班主任的感觉,倒是感觉像是二十多岁 刚大学毕业的。
配音的问题暂且不论。这种事情换做我是这个老师,我觉得我大概会这样处理,这种处理法是我在那个小说叫《尾巴》里面看的,那小说写得不错,建议大家都去看看,讲的是权力和技术监控的本质
先默不作声,调用监控,把事实搞清楚。
然后教导处的老师遣一个学生不认识的老师,故作神秘地找这个犯事的学生,别的不说,只说“教导处有人找”,让学生内心打鼓。
学生自己一个人去教导处,和别的学生不挨着,顾及学生面子。
完了学生往教导处悔过椅上一坐,别的不说,就摆事实讲道理,说你看,你是不在几点几点到哪哪哪去过,拿的个什么东西把哪扇玻璃打破的,我们都调查清楚了,你看我们没事儿找你过来干什么呢,所以你最好还是配合我们,如此这般如此这般。
这个过程中不拿出录像,如果学生自己悔过那么从轻处罚,要是死不认账,再把作为最后打击力量的录像拿出来。
这个老师在班里面大呼小叫,只有两种可能,一、监控不是有效监控;二、没有能够自己抓到十足的证据把破坏者找出来。所以才采用波及范围这么大,这么人尽皆知的方式
{kind=link}
{kind=link}
{kind=link}
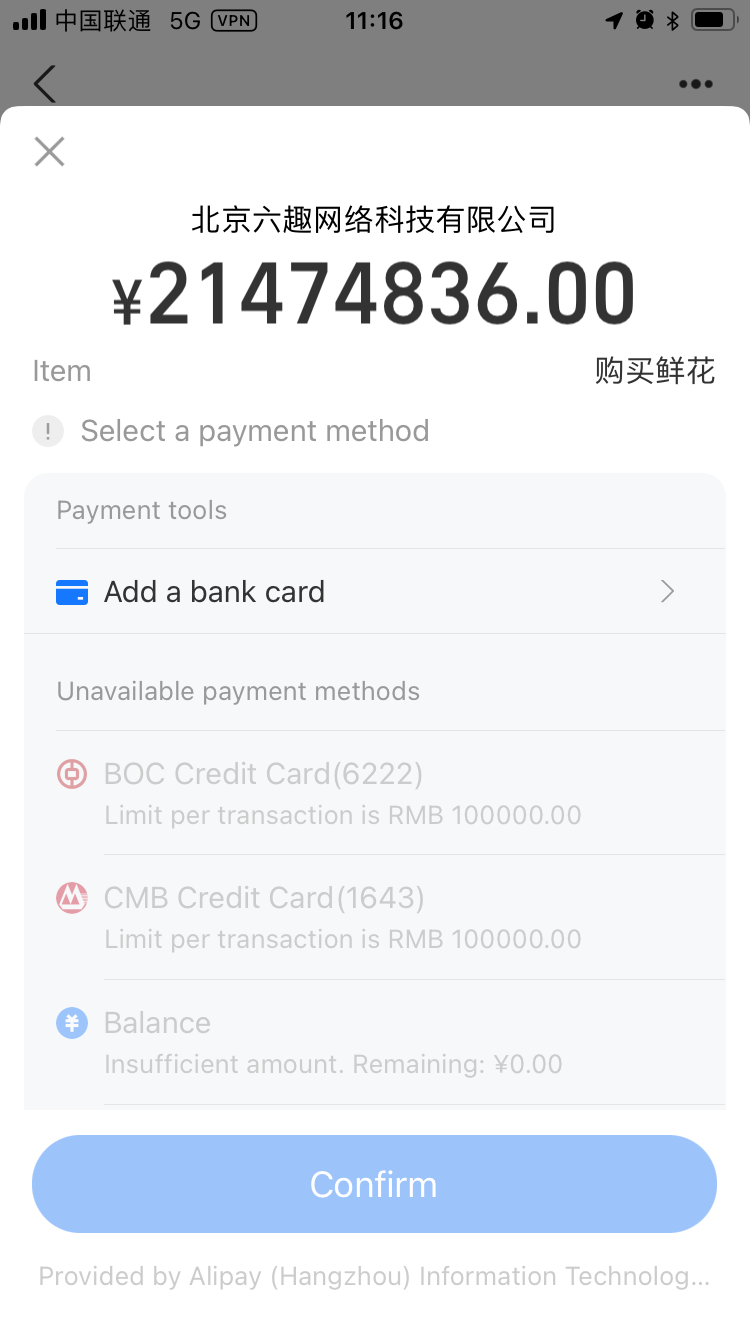
橙光网站的支付逻辑
首先服务器端是做了校验的:
- 测试过程中用网络请求放负数上去,服务器会把提交上去的控制符略掉只保留数字,如果服务器过滤之后的数字是合法的交易后的虚拟物品数量和下账的金额都是正确的(比如你输个 -1 提交上去,实际提交上去的订单是 1,交易成功,钱扣了,花花增加 1 个)。
- 测试过程中用网络请求放不合法的东西上去(比如汉字字符串),服务器端会返回拒绝
他的处理逻辑大概是这样:
上送之后服务器过滤之后接受整数,然后认定整数是以分为单位的金额,这个和银行的处理逻辑是类似的;
然后把数字最后两位直接去掉,这样计数单位就变成元,相当于直接向下取整,因为花花一块钱一个。如果你提交的数字包含辅币,那么实际收取的是向下取整的数字金额(就是只收取到元位),把金额传送给第三方支付工具比如支付宝让它收取。
然后下账,系统软件给账户当中加上整数对应的花花。
可以,看来这个流程是论证过的,比较健壮
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 玩
- Noteshelf 3
- 喜欢
- 昔涟/唐语歌/三月七
- 输入法
- 小鹤双拼
- 当前版本
- 0.1.0
春来遍是桃花水,不辨仙源何处寻
加入于 2024年03月
